
type
status
date
slug
summary
tags
category
icon
password
NLP经典案例:推文评论情绪提取
项目背景
"My ridiculous dog is amazing." [sentiment: positive]
由于所有推文每秒都在传播,很难判断特定推文背后的情绪是否会影响一家公司或一个人的品牌,因为它的病毒式传播(积极),或者因为它的负面基调而破坏利润。在决策和反应在几秒钟内创建和更新的时代,用语言捕捉情感非常重要。但是,哪些词实际上导致了情感描述呢?在本次比赛中,您需要选出推文中反映情绪的部分(单词或短语)。
利用这个广泛的推文数据集帮助您培养在这一重要领域的技能。努力提高你的技术,在这场比赛中占据榜首。推文中的哪些词语支持积极、消极或中立的情绪?您如何使用机器学习工具帮助做出决定?
在本次比赛中,我们从 Figure Eight 的 Data for Everyone 平台中提取了支持短语。该数据集的标题为“情感分析:具有现有情感标签的文本推文中的情感”,此处在知识共享署名 4.0 下使用。国际许可证。你在这次比赛中的目标是构建一个可以做同样事情的模型 - 查看给定推文的标记情绪,并找出最能支持它的单词或短语。
目录
- EDA(数据探索性分析)
- 语料库清洗
- 词频可视化
- 词云图
- NER模型建立
关于本项目
在此笔记中,我将简要解释数据集的结构。我将生成并分析元特征。然后,我将使用 Matplotlib、seaborn 和 Plotly 可视化数据集,以获得尽可能多的见解。我还将把这个问题作为 NER 问题来处理来构建模型
导入必要的库
下面是一个辅助函数,它生成随机颜色,可用于为您的绘图提供不同的颜色。随意使用它
读取数据
本项目数据集来源于kaggle竞赛平台,可公众号后台回复“推文情绪”即可获取数据集
所以我们在训练集中有 27486 条推文,在测试集中有 3535 条推文
我们在训练中有一个空值,因为值的测试字段是 NAN,我们将删除它
测试集中不存在空值
EDA(数据探索性分析)
Selected_text 是文本的子集
让我们看看推文在训练集中的分布
ㅤ | sentiment | text |
1 | neutral | 11117 |
2 | positive | 8582 |
0 | negative | 7781 |
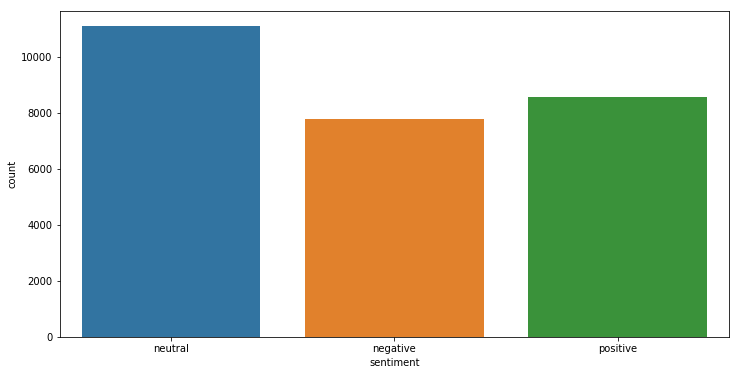
让我们画一个漏斗图以获得更好的可视化效果
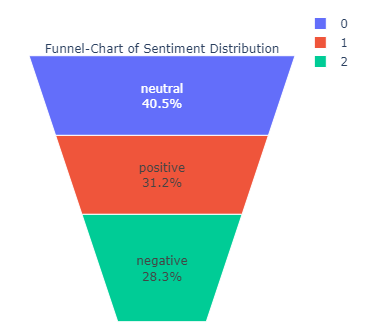
目前我们对数据了解多少:
在开始之前,让我们看一下我们已经了解的有关数据的一些知识,这些知识将帮助我们获得更多新的见解:
- 我们知道 selected_text 是文本的子集
- 我们知道 selected_text 只包含一段文本,即,它不会在两个句子之间跳转。例如:-如果文本是“在与供应商的会议中度过了整个上午,而我的老板对此不满意”他们。很有趣。 我早上还有其他计划”所选文本可以是“我的老板对他们不满意”。很有趣”或“很有趣”,但不能是“早上好,供应商和我的老板,
- 我们知道中性推文的文本和 selected_text 之间的 jaccard 相似度为 97%
- 另外,有些行中 selected_text 从单词之间开始,因此 selected_texts 并不总是有意义,因为我们不知道是否测试集的输出是否包含这些差异,我们不确定预处理和删除标点符号是否是一个好主意
生成元特征
在本笔记本的先前版本中,我使用所选文本和主要文本中的单词数、文本中的单词长度和选择作为主要元特征,但在本次比赛的背景下,我们必须预测 selected_text 这是一个文本的子集,生成的更有用的功能将是:
- Selected_text 和 Text 的字数差异
- 文本和 Selected_text 之间的 Jaccard 相似度分数
因此,生成我们之前使用过的特征对我们来说没有用,因为它们在这里并不重要
以下是 Jaccard 相似度的介绍:https://www.geeksforgeeks.org/find-the-jaccard-index-and-jaccard-distance-Between-the-two-given-sets/
我们看一下Meta-Features的分布
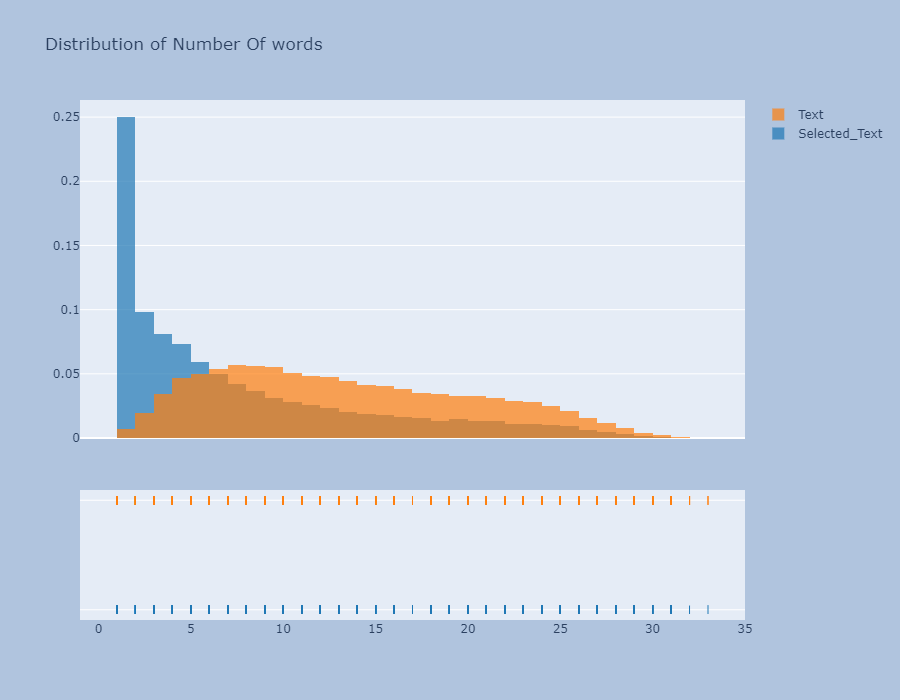
- 字数图非常有趣,字数大于 25 的推文非常少,因此字数分布图是右偏的
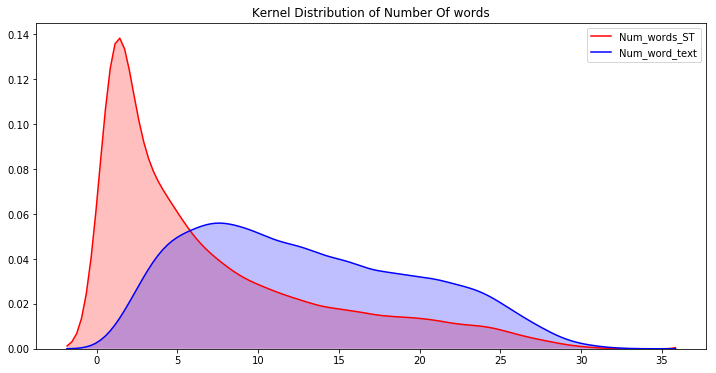
现在看到不同情绪的字数和jaccard分数的差异会更有趣
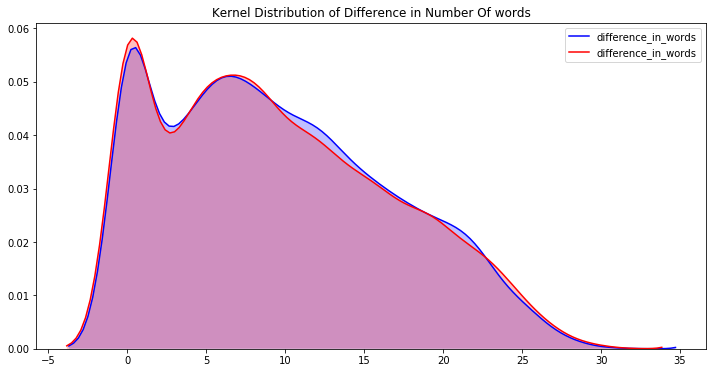

我无法绘制中性推文的 kde 图,因为大多数字数差异值为零。我们现在可以清楚地看到这一点,如果我们一开始就使用了该功能,我们就会知道对于中性推文来说,文本和所选文本大多相同,因此在执行 EDA 时牢记最终目标始终很重要
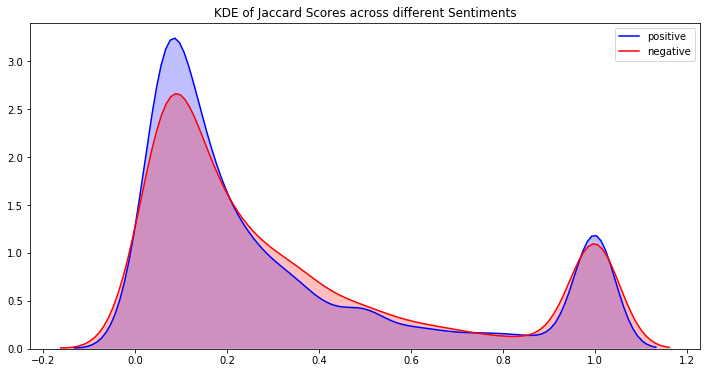
出于同样的原因,我无法绘制中立推文的 jaccard_scores 的 kde,因此我将绘制分布图

我们可以在这里看到一些有趣的趋势:
- 正面和负面推文具有高峰度,因此值集中在窄和高密度两个区域
- 中性推文具有较低的峰度值,并且其密度波动接近 1
定义解释:
- 峰度是分布的峰值程度以及围绕该峰值的分布程度的度量
- 偏度衡量曲线偏离正态分布的程度
EDA结论
我们可以从 jaccard 分数图中看到,分数为 1 附近有负图和正图的峰值。这意味着存在一组推文,其中文本和所选文本之间存在高度相似性,如果我们可以找到这些聚类,那么我们可以预测这些推文的选定文本的文本,无论片段如何
让我们看看是否可以找到这些簇,一个有趣的想法是检查文本中单词数少于 3 个的推文,因为那里的文本可能完全用作文本
我们可以看到文本和所选文本之间存在相似性。让我们仔细看看
因此很明显,大多数时候,文本被用作选定文本。我们可以通过预处理字长小于3的文本来改进这一点。我们将记住这些信息并在模型构建中使用它。
清理语料库
现在,在我们深入从文本和选定文本中的单词中提取信息之前,让我们首先清理数据。
我们的目标选定文本中最常见的单词
Index | Common_words | count |
0 | i | 7200 |
1 | to | 5305 |
2 | the | 4590 |
3 | a | 3538 |
4 | my | 2783 |
5 | you | 2624 |
6 | and | 2321 |
7 | it | 2158 |
8 | is | 2115 |
9 | in | 1986 |
10 | for | 1854 |
11 | im | 1676 |
12 | of | 1638 |
13 | me | 1540 |
14 | on | 1488 |
15 | so | 1410 |
16 | have | 1345 |
17 | that | 1297 |
18 | but | 1267 |
19 | good | 1251 |
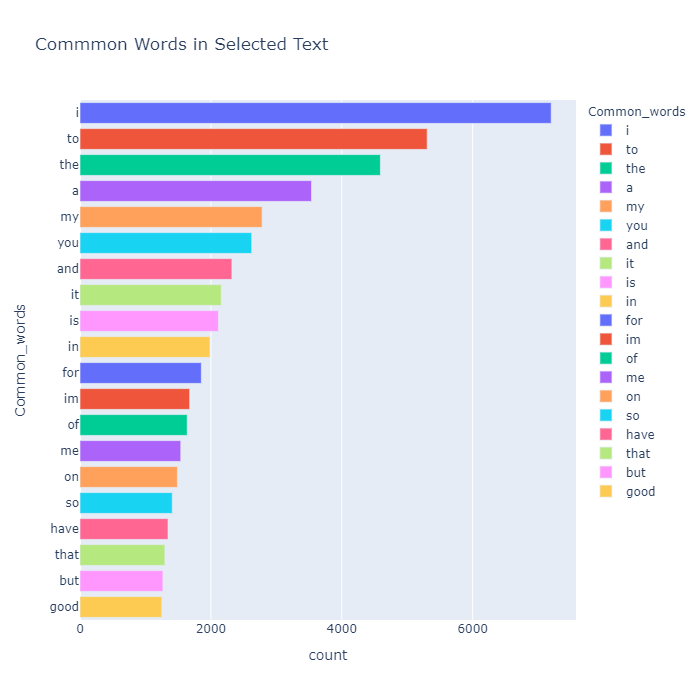
哎呀!当我们清理数据集时,我们没有删除停用词,因此我们可以看到最常见的词是 'to' 。删除停用词后重试
Index | Common_words | count |
1 | good | 1251 |
2 | day | 1058 |
3 | love | 909 |
4 | happy | 852 |
5 | like | 774 |
6 | get | 772 |
7 | dont | 765 |
8 | go | 700 |
9 | cant | 613 |
10 | work | 612 |
11 | going | 592 |
12 | today | 564 |
13 | got | 558 |
14 | one | 538 |
15 | time | 534 |
16 | thanks | 532 |
17 | lol | 528 |
18 | really | 520 |
19 | u | 519 |
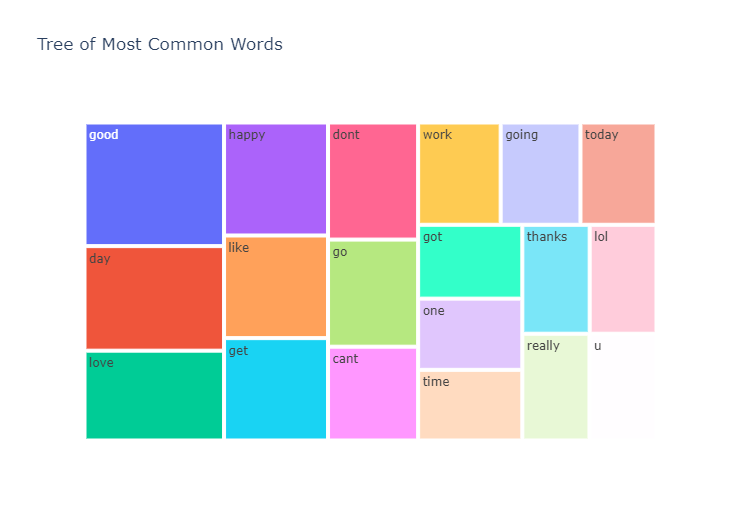
文本中最常见的单词
我们还看一下 Text 中最常见的单词
Index | Common_words | count |
1 | day | 2044 |
2 | good | 1549 |
3 | get | 1426 |
4 | like | 1346 |
5 | go | 1267 |
6 | dont | 1200 |
7 | love | 1122 |
8 | work | 1112 |
9 | going | 1096 |
10 | today | 1096 |
11 | got | 1072 |
12 | cant | 1020 |
13 | happy | 976 |
14 | one | 971 |
15 | lol | 948 |
16 | time | 942 |
17 | know | 930 |
18 | u | 923 |
19 | really | 908 |
20 | back | 891 |
21 | see | 797 |
22 | well | 744 |
23 | new | 740 |
24 | night | 737 |
所以前两个常见词是我,所以我删除了它并从第二行获取数据
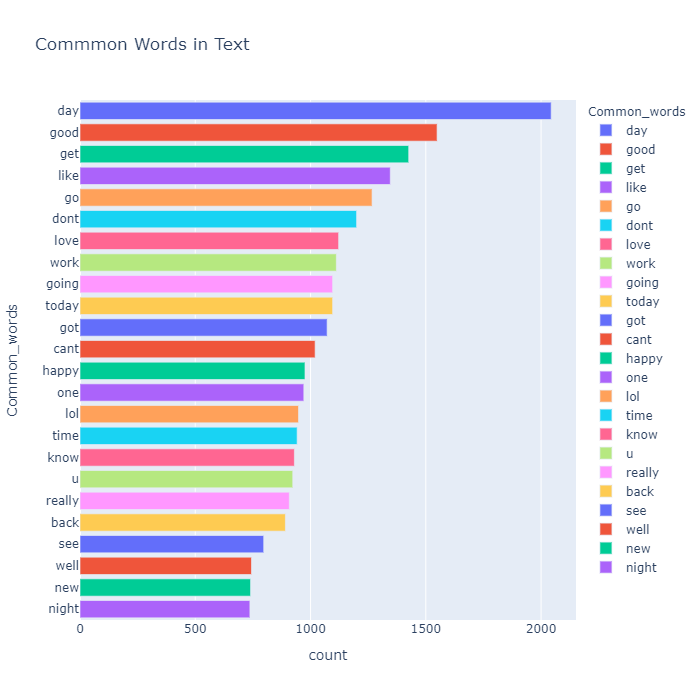
所以我们可以看到所选文本和文本中最常见的单词几乎相同,这是显而易见的
最常用的词 情感明智
让我们看看不同情绪中最常见的单词
Index | Common_words | count |
0 | good | 826 |
1 | happy | 730 |
2 | love | 697 |
3 | day | 456 |
4 | thanks | 439 |
5 | great | 364 |
6 | fun | 287 |
7 | nice | 267 |
8 | mothers | 259 |
9 | hope | 245 |
10 | awesome | 232 |
11 | im | 185 |
12 | thank | 180 |
13 | like | 167 |
14 | best | 154 |
15 | wish | 152 |
16 | amazing | 135 |
17 | really | 128 |
18 | better | 125 |
19 | cool | 119 |

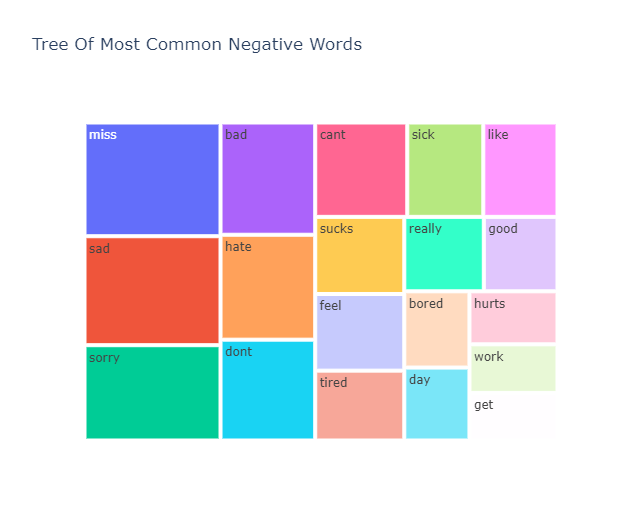
Index | Common_words | count |
1 | miss | 358 |
2 | sad | 343 |
3 | sorry | 300 |
4 | bad | 246 |
5 | hate | 230 |
6 | dont | 221 |
7 | cant | 201 |
8 | sick | 166 |
9 | like | 162 |
10 | sucks | 159 |
11 | feel | 158 |
12 | tired | 144 |
13 | really | 137 |
14 | good | 127 |
15 | bored | 115 |
16 | day | 110 |
17 | hurts | 108 |
18 | work | 99 |
19 | get | 97 |
Index | Common_words | count |
1 | get | 612 |
2 | go | 569 |
3 | day | 492 |
4 | dont | 482 |
5 | going | 472 |
6 | work | 467 |
7 | like | 445 |
8 | got | 441 |
9 | today | 427 |
10 | lol | 427 |
11 | time | 413 |
12 | know | 407 |
13 | back | 402 |
14 | one | 394 |
15 | u | 376 |
16 | see | 349 |
17 | cant | 339 |
18 | home | 335 |
19 | want | 319 |
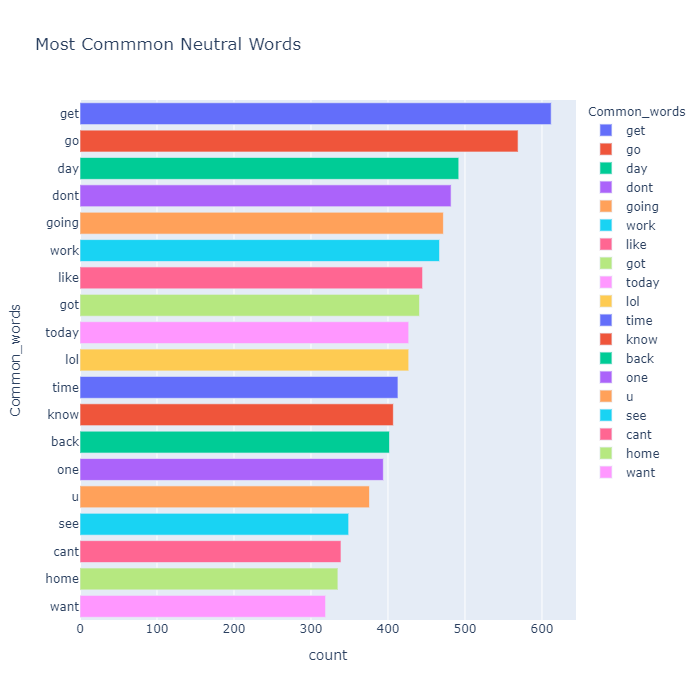
我们可以看到 get、go、dont、got、u、cant、lol、like 等词在这三个细分市场中都很常见。这很有趣,因为像 dont 和 cant 这样的词更多的是消极的性质,而像 lol 这样的词更多的是积极的性质。这是否意味着我们的数据被错误地标记了,在 N-gram 分析后我们将对此有更多的见解
看到不同情绪所特有的词会很有趣
让我们看看每个片段中的独特单词
我们将按以下顺序查看每个片段中的唯一单词:
- 积极的
- 消极的
- 中性的
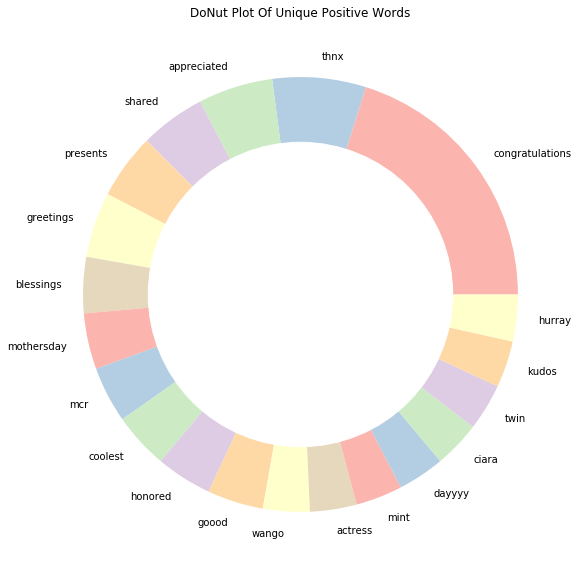
积极的推文
Index | words | count |
0 | congratulations | 29 |
1 | thnx | 10 |
2 | appreciated | 8 |
3 | shared | 7 |
4 | presents | 7 |
5 | greetings | 7 |
6 | blessings | 6 |
7 | mothersday | 6 |
8 | mcr | 6 |
9 | coolest | 6 |
10 | honored | 6 |
11 | goood | 6 |
12 | wango | 5 |
13 | actress | 5 |
14 | mint | 5 |
15 | dayyyy | 5 |
16 | ciara | 5 |
17 | twin | 5 |
18 | kudos | 5 |
19 | hurray | 5 |

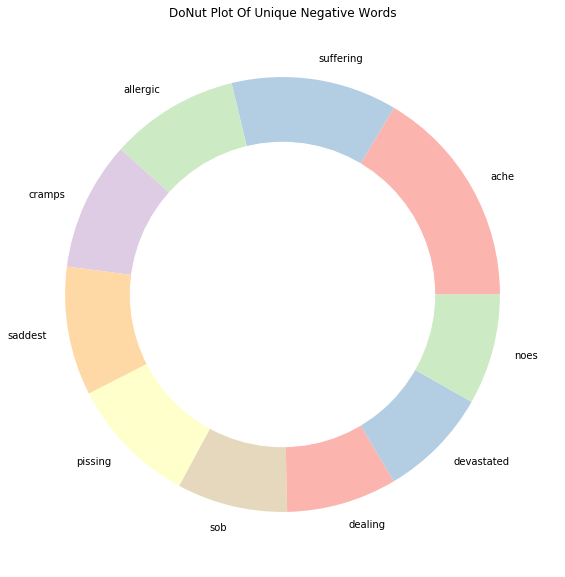
Index | words | count |
0 | ache | 12 |
1 | suffering | 9 |
2 | allergic | 7 |
3 | cramps | 7 |
4 | saddest | 7 |
5 | pissing | 7 |
6 | sob | 6 |
7 | dealing | 6 |
8 | devastated | 6 |
9 | noes | 6 |
Index | words | count |
0 | settings | 9 |
1 | explain | 7 |
2 | mite | 6 |
3 | hiya | 6 |
4 | reader | 5 |
5 | pr | 5 |
6 | sorta | 5 |
7 | fathers | 5 |
8 | enterprise | 5 |
9 | guessed | 5 |
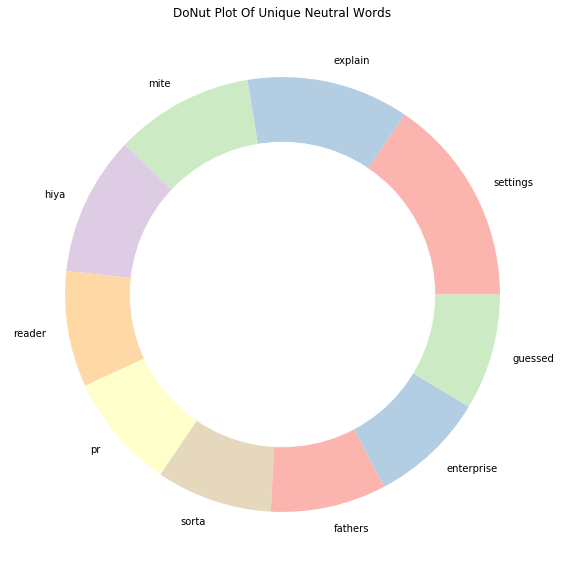
通过查看每种情绪的独特单词,我们现在对数据有了更清晰的了解,这些独特的单词是推文情绪的强有力决定因素
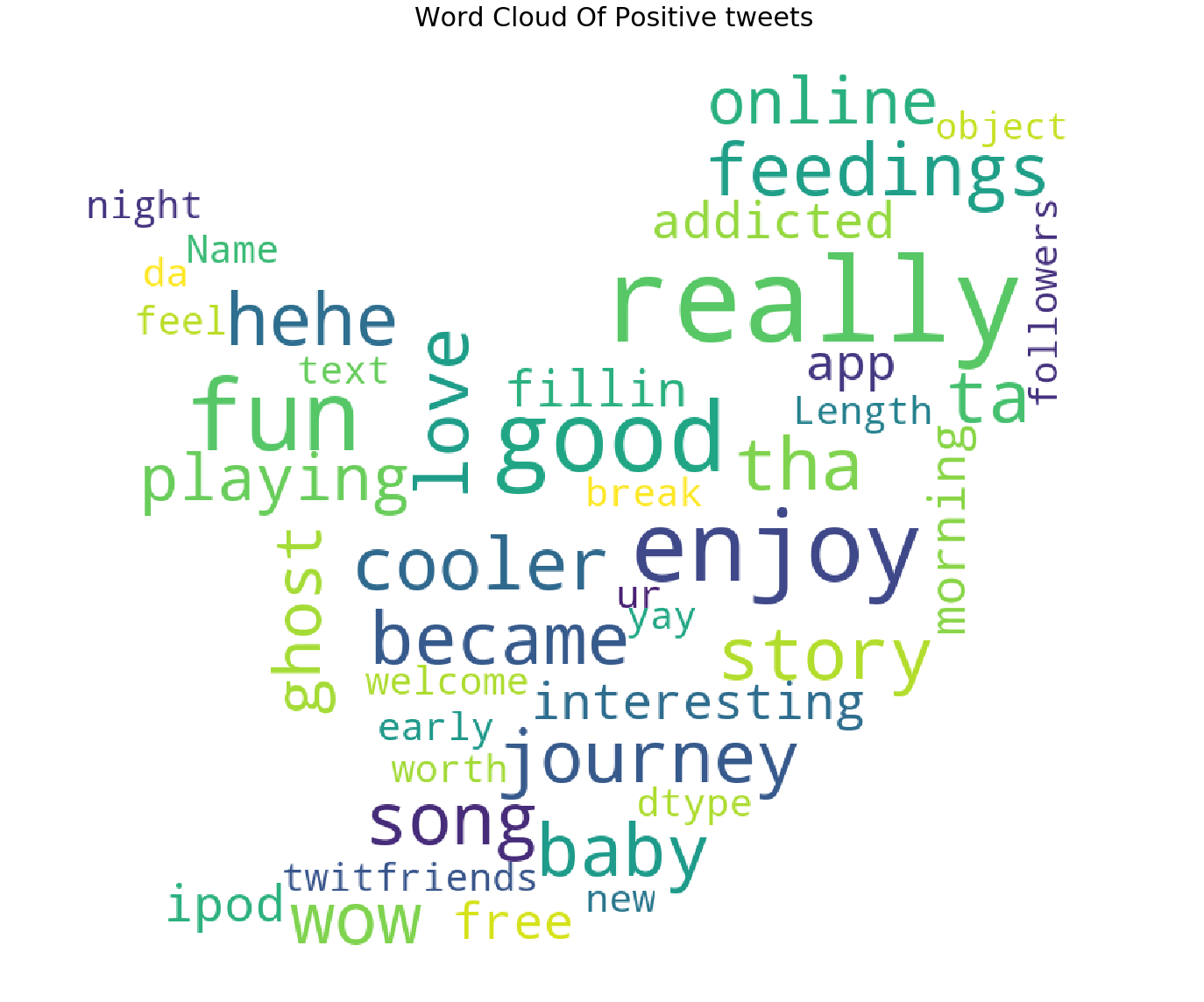
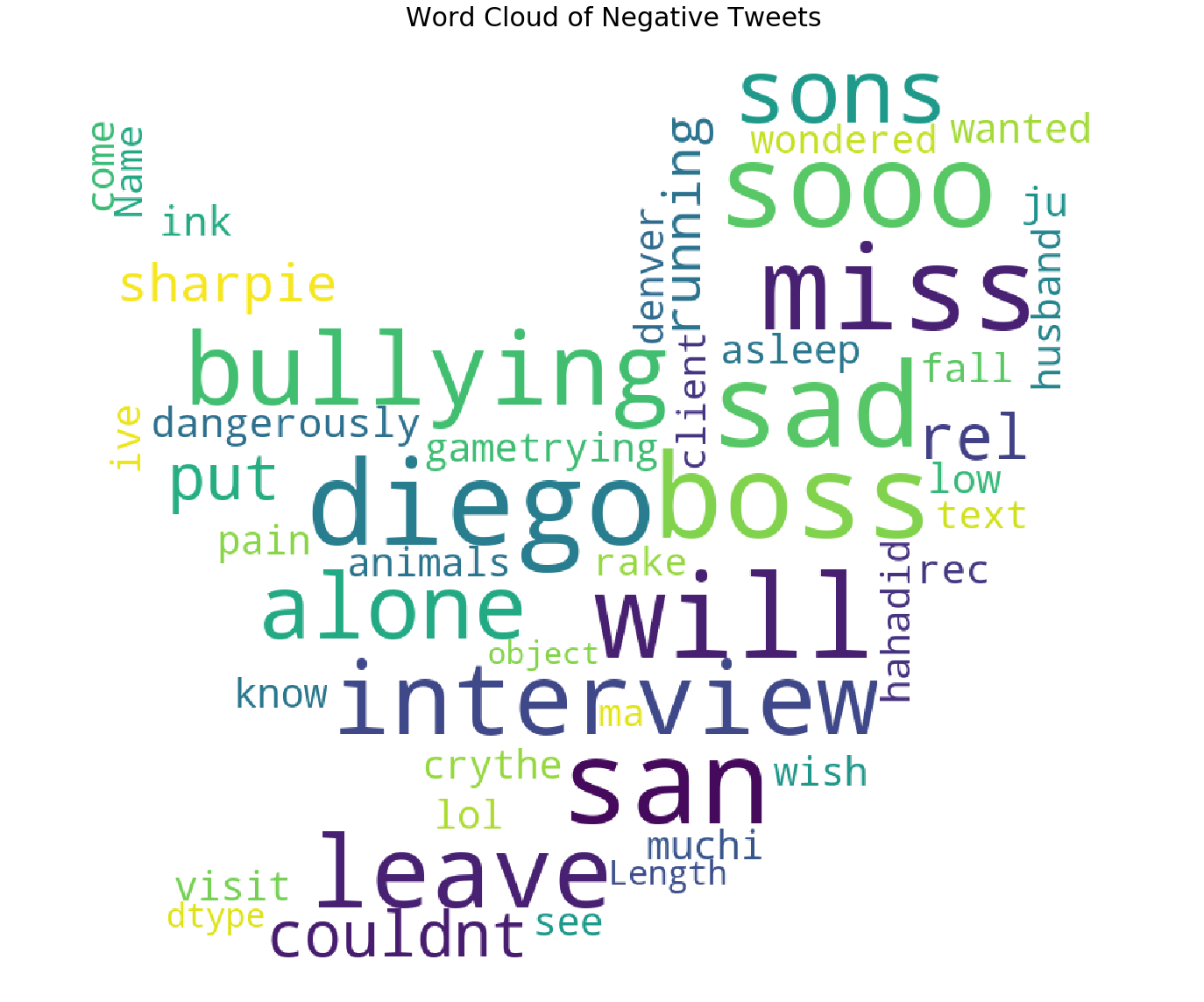
词云图绘制
我们将按以下顺序构建词云:
- 中性推文的词云
- 积极推文的词云
- 负面推文的词云
我添加了更多单词,如 im 、 u (我们说这些单词出现在最常见的单词中,干扰了我们的分析)作为停用词
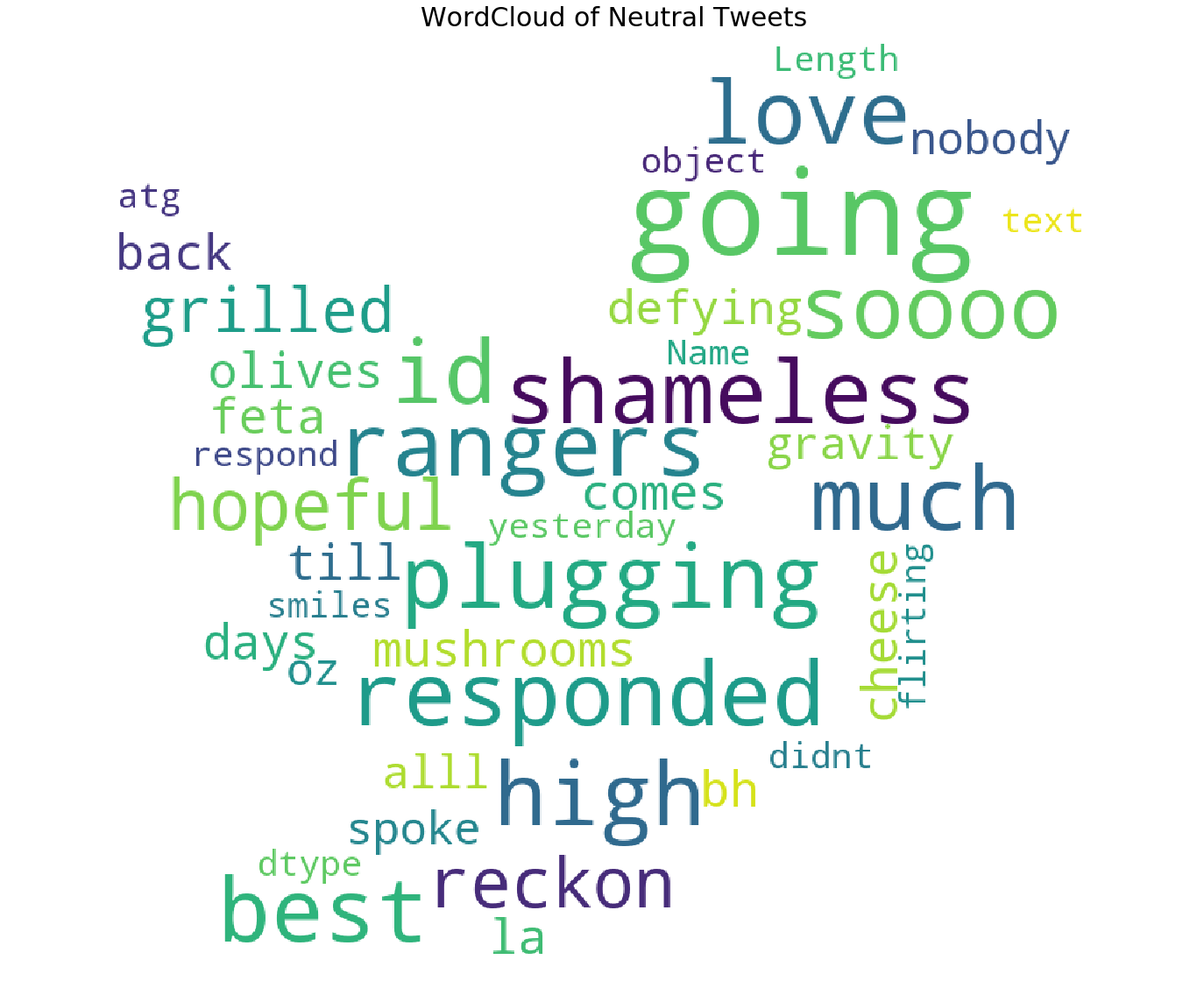
中性推文云
我们已经形象化了最常见的否定词,但词云为我们提供了更多的清晰度
模型构建
1) 将问题建模为 NER
命名实体识别 (NER) 是一个标准的 NLP 问题,涉及从文本块中识别命名实体(人物、地点、组织等),并将它们分类为一组预定义的类别。
为了理解 NER,这里有一篇非常好的文章:https://towardsdatascience.com/named-entity-recognition-with-nltk-and-spacy-8c4a7d88e7da
我们将使用 spacy 来创建我们自己的定制 NER 模型(针对每个情绪单独)。这种方法的动机当然是 Rohit Singh 共享的内核。
我的解决方案有何不同:
- 由于 jaccard 的高度相似性,我将使用文本作为所有中性推文的 selected_text
- 此外,我还将使用文本作为文本中字数少于 3 个的所有推文的 selected_text,如前所述
- 我将为正面和负面推文训练两种不同的模型
- 我不会预处理数据,因为所选文本包含原始文本
要完全了解如何使用自定义输入训练 spacy NER,请阅读 spacy 文档以及本笔记本中的代码演示:https://spacy.io/usage/training#ner 按照更新 Spacy NER
正面和负面推文的训练模型
使用经过训练的模型进行预测
Index | textID | selected_text |
0 | f87dea47db | Last session of the day http://twitpic.com/67ezh |
1 | 96d74cb729 | exciting |
2 | eee518ae67 | Recession |
3 | 01082688c6 | happy bday! |
4 | 33987a8ee5 | I like it!! |
5 | 726e501993 | visitors! |
6 | 261932614e | HATES |
7 | afa11da83f | blocked |
8 | e64208b4ef | and within a short time of the last clue all... |
9 | 37bcad24ca | What did you get? My day is alright.. haven't... |
- Author:Gordon
- URL:https://blog.csdn.net/EasyMCM?spm=1010.2135.3001.5343/article/15e68400-c405-8084-9884-e0f72931aff8
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!